

鱼羊 发自 凹非寺
量子位 报道 | 公众号 QbitAI
实验室一块GPU都没有怎么做深度学习?
如果让莱斯大学和英特尔的研究人员来回答,答案大概是:用CPU啊。
莱斯大学和英特尔的最新研究证明,无需专门的加速硬件(如GPU),也可以加速深度学习。
算法名为SLIDE。
研究人员称,SLIDE是第一个基于CPU的深度学习智能算法,并且,在具有大型全连接架构的行业级推荐数据集上,SLIDE训练深度神经网络的速度甚至超过了GPU。
代码已开源。
基于局部敏感哈希
摆脱GPU的核心思想,是利用局部敏感哈希来摆脱矩阵乘法。
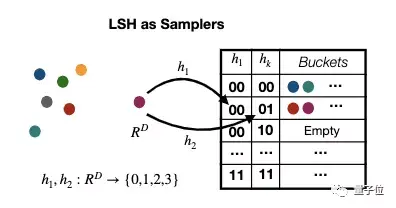
代码采用C++编写。
论文一作Beidi Chen介绍:
基于TensorFlow和PyTorch来实现SLIDE算法是没有意义的,因为那必须把问题转换成矩阵乘法问题,而这一点恰恰是我们想要摆脱的。
在架构上,SLIDE的中心模块是神经网络。网络的每个层模块由神经元和一些哈希表组成,神经元ID被哈希到其中。
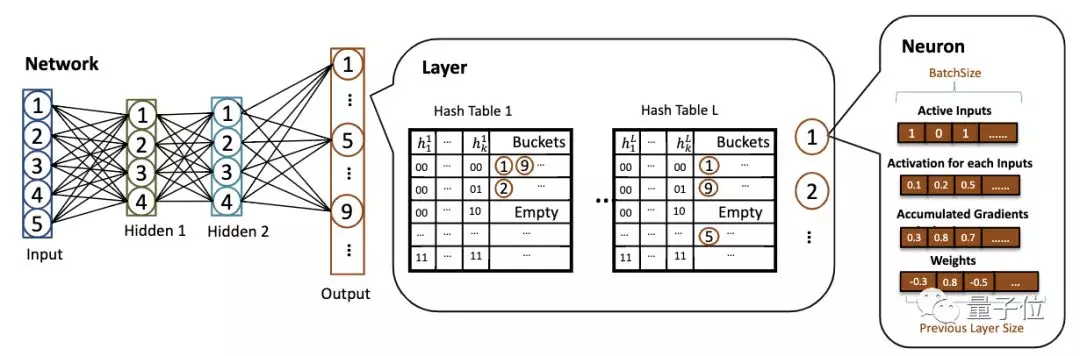
每个神经元模块都包含:
- 一个二进制数组,提示该神经元是否对于batch中的每一个输入都有效
- batch中的每一个输入的activation
- batch中每个输入的累积梯度
- 与上一层的连接权重
最后一个数组的长度等于上一层中神经元的数量。
每层中的LSH哈希表构造都是一次性操作,可以与该层中不同神经元上的多个线程并行。
论文作者之一、莱斯大学助理教授Anshumali Shrivastava表示,SLIDE相对于反向传播的最大优势就在于数据并行。
举个例子,数据并行的情况下,要训练两个数据实例,一个是猫的图像,另一个是公共汽车的图像,它们可能会激活不同的神经元,而SLIDE可以分别独立地更新、训练它们。
如此,就能更好地利用CPU的并行性。
不过,与GPU相比,该方法对内存要求较高。
Shrivastava也提到,在与英特尔的合作中,他们针对SLIDE,对CPU进行了优化,比如支持Kernel Hugepages以减少缓存丢失。这些优化使得SLIDE的性能提高了约30%。
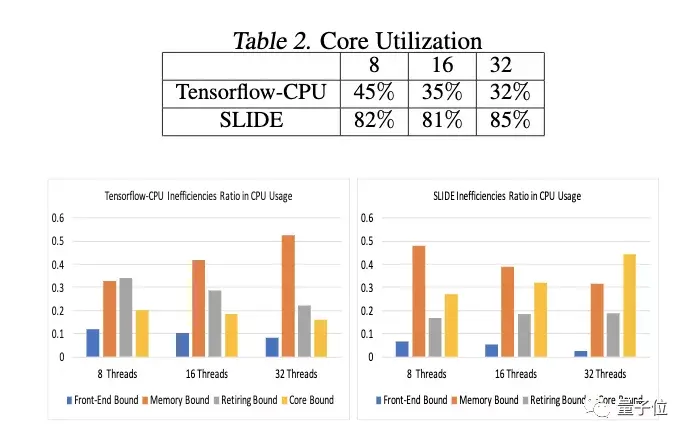
实验结果
所以,与依赖GPU的深度学习相比,SLIDE到底表现如何?
研究人员在Delicious-200K和Amazon-670K这两个大型数据集上进行了验证。
实验配置,是2个22核/44线程处理器(Intel Xeon E5-2699A v4 2.40GHz),和英伟达TeslaV100 Volta 32GB GPU。
结果表明,在任意精度上,CPU上的SLIDE总是比V100上基于TensorFlow的GPU算法快。
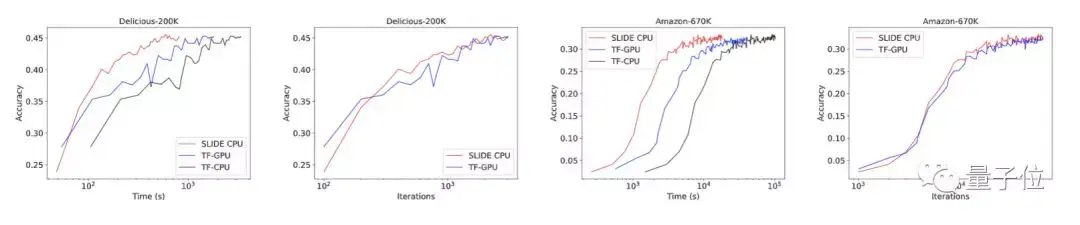
在Delicious-200K数据集上,SLIDE比TF-GPU快1.8倍;而在算力要求更高的Amazon-670K数据集上,SLIDE的速度更是TF-GPU的2.7倍。
其大部分计算优势,来自于对输出层中一小部分激活神经元的采样。
而在相同的CPU上,SLIDE要比基于TensorFlow的算法快10倍以上。
网友:英特尔的广告?
在CPU上跑深度学习能快过GPU,这样的结论立刻吸引住了网友们的目光。
有网友分析说:
该方法不仅使用了哈希表,其速度之快还得归功于OpenMP的硬件多核优化。(OpenMP是一套支持跨平台共享内存方式的多线程并发的编程API)
看起来在小型DNN中是非常有前途的替代方案。不过,问题在于,该方法是否可以推广到其他CPU架构中?这种方法中还是存在巨大的冲突和牺牲准确性的风险。

还有人表示,在与作者的交流中,他认为该方法主要适用于宽网络,否则哈希表的开销会大于其收益。那么至少,在架构探索中,该方法提供了探索更宽网络的可能性。
不过,也有网友提出了更尖锐的质疑:怕不是来给英特尔打广告的。
1、预处理步骤看上去开销高昂。
2、采用了特殊优化的架构,那么性能增益有多少是归功于方法本身的?
3、缺少分别在CPU和GPU上运行SLIDE的比较。

所以,结果到底靠不靠谱?不妨戳进文末论文链接阅读原文,发表你的见解~
传送门
论文地址:https://arxiv.org/abs/1903.03129
GitHub地址:https://github.com/keroro824/HashingDeepLearning
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态







