

本教程将解释如何使用单个或多个配置中的AMD GPU设置用于训练的神经网络环境。
在软件方面:我们将使用Docker,在ROCm内核之上运行Keras(Tensorflow v1.12.0作为后端)。
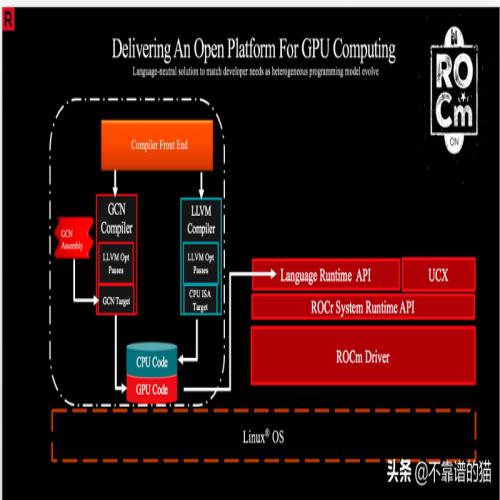
要安装和部署ROCm,需要特定的硬件/软件配置。
硬件要求
官方文档(ROCm v2.1)建议使用以下硬件解决方案。
支持的CPU
支持PCIe Gen3 + PCIe Atomics的CPU有:
- AMD Ryzen CPU;
- AMD Ryzen APU中的CPU;
- AMD Ryzen Threadripper CPU
- AMD EPYC CPU;
- Intel Xeon E7 v3或更新的CPU;
- Intel Xeon E5 v3或更新的CPU;
- Intel Xeon E3 v3或更新的CPU;
- Intel Core i7 v4(i7-4xxx),Core i5 v4(i5-4xxx),Core i3 v4(i5-4xxx)或更新的CPU(即Haswell系列或更新版本)。
- 一些Ivy Bridge-E系统
支持的GPU
ROCm正式支持使用以下芯片的AMD GPU:
- GFX8 GPU
- “斐济”芯片,如AMD Radeon R9 Fury X和Radeon Instinct MI8
- “Polaris 10”芯片,例如AMD Radeon RX 480/580和Radeon Instinct MI6
- “Polaris 11”芯片,例如AMD Radeon RX 470/570和Radeon Pro WX 4100
- “Polaris 12”芯片,例如AMD Radeon RX 550和Radeon RX 540
- GFX9 GPU
- “Vega 10”芯片,例如AMD Radeon RX Vega 64和Radeon Instinct MI25
- “Vega 7nm”芯片(Radeon Instinct MI50,Radeon VII)
软件要求
在软件方面,仅在基于Linux的系统中支持当前版本的ROCm(v2.1)。
ROCm 2.1.x平台支持以下操作系统:
- Ubuntu 16.04.x和18.04.x(16.04.3及更高版本或内核4.13及更高版本)
- CentOS 7.4,7.5和7.6(使用devtoolset-7 runtime支持)
- RHEL 7.4,7.5和7.6(使用devtoolset-7 runtime支持)
测试设置
硬件
- CPU:Intel Xeon E5-2630L
- RAM:2 x 8 GB
- 主板:微星X99A Krait版
- GPU:2 x RX480 8GB + 1 x RX580 4GB
- SSD:三星850 Evo(256 GB)
- HDD:WDC 1TB
软件
- 操作系统:Ubuntu 18.04 LTS
ROCm安装
为了使一切正常工作,建议在新安装的操作系统中启动安装过程。以下步骤指的是ubuntu1804 LTS操作系统,其他操作系统请参考官方文档。
第一步是安装ROCm内核和依赖项:
更新您的系统
打开一个新终端 CTRL + ALT + T
sudo apt update sudo apt dist-upgrade sudo apt install libnuma-dev sudo reboot
添加ROCm apt repository
要下载并安装ROCm堆栈,需要添加相关的repositories:
wget -qO - http://repo.radeon.com/rocm/apt/debian/rocm.gpg.key | sudo apt-key add - echo 'deb [arch=amd64] http://repo.radeon.com/rocm/apt/debian/ xenial main' | sudo tee /etc/apt/sources.list.d/rocm.list

安装ROCm
现在需要更新apt repository列表并安装rocm-dkms元数据包:
sudo apt update sudo apt install rocm-dkms
设置权限
官方文档建议创建一个新video组,以便使用当前用户访问GPU资源。
首先,检查系统中的组,使用:
groups
然后添加到video组:
sudo usermod -a -G video $LOGNAME
您可能希望确保您添加到系统中的任何未来用户在默认情况下都被放入“video”组中。为此,您可以运行以下命令:
echo 'ADD_EXTRA_GROUPS=1' | sudo tee -a /etc/adduser.conf echo 'EXTRA_GROUPS=video' | sudo tee -a /etc/adduser.conf

然后重启系统:
reboot
测试ROCm stack
现在建议使用以下命令测试ROCm安装。
打开一个新终端CTRL + ALT + T ,使用以下命令:
/opt/rocm/bin/rocminfo
然后再检查一下
/opt/rocm/opencl/bin/x86_64/clinfo
官方文档最后建议将ROCm二进制文件添加到PATH:
echo 'export PATH=$PATH:/opt/rocm/bin:/opt/rocm/profiler/bin:/opt/rocm/opencl/bin/x86_64' | sudo tee -a /etc/profile.d/rocm.sh
ROCm已正确安装在您的系统和命令中:
rocm-smi
应显示您的硬件信息和统计信息:

Tensorflow Docker
让ROCm + Tensorflow后端工作起来最快、最可靠的方法是使用AMD开发人员提供的docker镜像。
安装Docker CE
首先,需要安装Docker。为此,请按照Ubuntu系统的说明操作:https://docs.docker.com/install/linux/docker-ce/ubuntu/
Pull ROCm Tensorflow image
现在是pull AMD开发人员提供的Tensorflow docker的时候了。
打开一个新终端CTRL + ALT + T:
docker pull rocm/tensorflow
创建持久空间
由于Docker容器的短暂性质,一旦docker会话关闭,所有存储的修改和文件将随容器一起删除。
因此,在物理驱动器中创建用于存储文件和Jupyter notebooks的持久空间非常有用。更简单的方法是创建一个用docker容器初始化的文件夹。为此,请执行以下命令:
mkdir /home/$LOGNAME/tf_docker_share
此命令将创建一个名为tf_docker_share的文件夹,用于存储和查看在docker中创建的数据。
启动Docker
现在,在新的容器会话中执行镜像。
docker run -i -t \ --network=host \ --device=/dev/kfd \ --device=/dev/dri \ --group-add video \ --cap-add=SYS_PTRACE \ --security-opt seccomp=unconfined \ --workdir=/tf_docker_share \ -v $HOME/tf_docker_share:/tf_docker_share rocm/tensorflow:latest /bin/bash

docker在/tf_docker_share目录下执行,您应该会看到类似的内容:

这意味着您现在在Tensorflow-ROCm虚拟系统内运行。
安装Jupyter
Jupyter是一种非常有用的工具,用于神经网络的开发、调试和测试。不幸的是,在ROCm团队发布的Tensorflow-ROCm Docker镜像上,它目前没有作为默认安装。因此需要手动安装Jupyter。
为了做到这一点,在Tensorflow-ROCm虚拟系统提示符下,
1.使用以下命令:
pip3 install jupyter
它会将Jupyter包安装到虚拟系统中。
2.打开一个新终端CTRL + ALT + T 。
找到CONTAINER ID:
docker ps
应出现一个类似于以下内容的表:

第一列表示已执行容器的Container ID。
3.从同一终端执行:
docker commit <container-id> rocm/tensorflow:<tag>
其中,tag值是一个任意名称,例如personal。
4.要从同一终端仔细检查镜像是否已正确生成,请使用命令:
docker images
应该生成一个类似于以下的表:
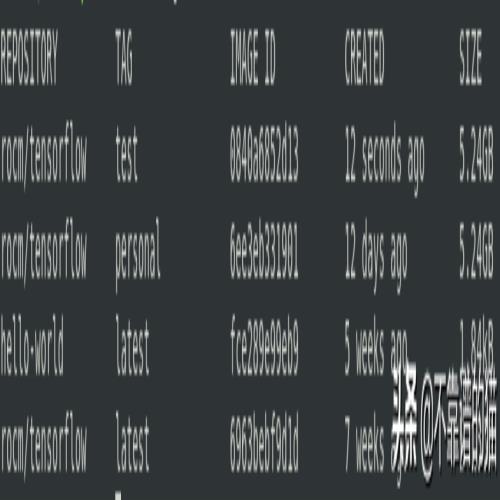
值得注意的是,我们将在本教程的其余部分中引用这个新生成的镜像。
要使用的新docker run命令如下所示:
docker run -i -t \ --network=host \ --device=/dev/kfd \ --device=/dev/dri \ --group-add video \ --cap-add=SYS_PTRACE \ --security-opt seccomp=unconfined \ --workdir=/tf_docker_share \ -v $HOME/tf_docker_share:/tf_docker_share rocm/tensorflow:<tag> /bin/bash

进入Jupyter notebook环境
我们终于可以进入Jupyter环境了。在其中,我们将使用Tensorflow v1.12作为后端和Keras作为前端创建第一个神经网络。
Cleaning
首先关闭所有以前执行的Docker容器。
1.检查已打开的容器:
docker ps
2.关闭所有Docker容器:
docker container stop <container-id1> <container-id2> ... <container-idn>
3.关闭所有已经打开的终端。
执行Jupyter
让我们打开一个新的终端CTRL + ALT + T :
- 运行一个新的Docker容器(personal标记将用作默认值):
docker run -i -t \ --network=host \ --device=/dev/kfd \ --device=/dev/dri \ --group-add video \ --cap-add=SYS_PTRACE \ --security-opt seccomp=unconfined \ --workdir=/tf_docker_share \ -v $HOME/tf_docker_share:/tf_docker_share rocm/tensorflow:personal /bin/bash

您应该登录到Tensorflow-ROCm docker容器提示符。

2.执行Jupyter notebook:
jupyter notebook --allow-root --port=8889
应出现一个新的浏览器窗口,类似于以下内容:
如果未自动出现,请返回jupyter notebook执行命令的终端。在底部,有一个链接。

典型的Jupyter notebook输出。示例链接位于底部
用Keras训练神经网络
在本教程的最后一节中,我们将在MNIST机器学习数据集上训练一个简单的神经网络。我们将首先建立一个全连接神经网络。
全连接神经网络
让我们通过从Jupyter根目录的右上角菜单中选择Python3来创建一个新的notebook。
应在新的浏览器选项卡中弹出一个新的Jupiter notebook。单击Untitled窗口的左上角将其重命名为fc_network。
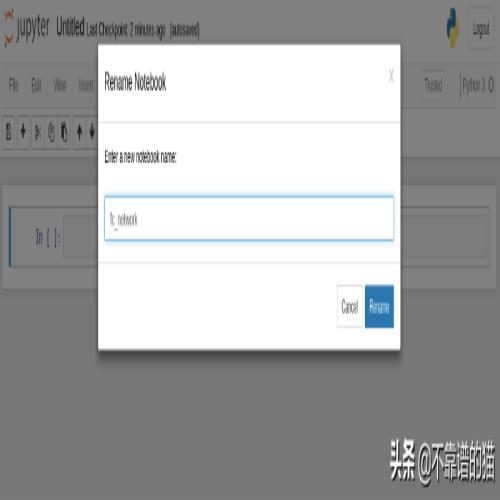
我们来看看Tensorflow后端。在第一个单元格插入:
import tensorflow as tf; print(tf.__version__)
然后按下SHIFT + ENTER执行。输出应如下所示:
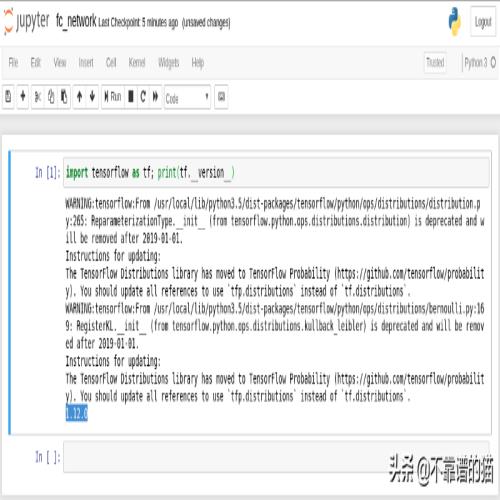
我们正在使用Tensorflow v1.12.0。
让我们导入一些有用的Python库,下一步使用:
from tensorflow.keras.datasets import mnist from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Dropout from tensorflow.keras.optimizers import RMSprop from tensorflow.keras.utils import to_categorical

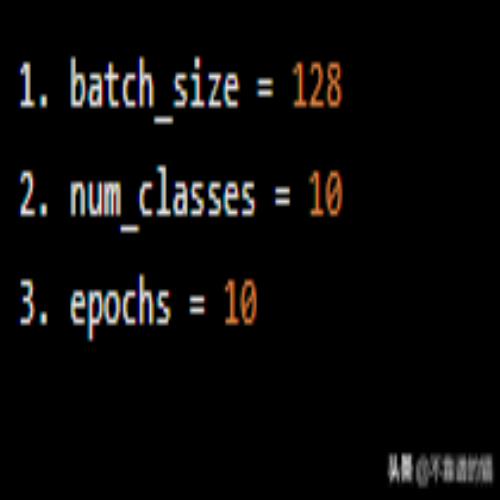
我们设置batch size,epochs和类数量。
batch_size = 128 num_classes = 10 epochs = 10
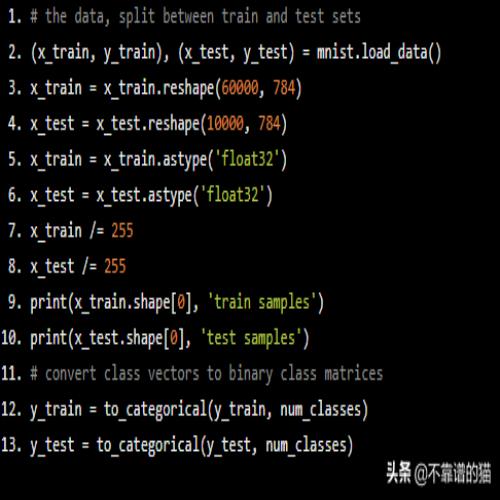
我们现在预处理输入,将它们加载到系统内存中。
convert class vectors to binary class matrices y_train = to_categorical(y_train, num_classes) y_test = to_categorical(y_test, num_classes)
是时候定义神经网络架构了:
model = Sequential() model.add(Dense(512, activation='relu', input_shape=(784,))) model.add(Dropout(0.2)) model.add(Dense(512, activation='relu')) model.add(Dropout(0.2)) model.add(Dense(num_classes, activation='softmax'))

我们将使用一个非常简单的,两层全连接网络,每层有512个神经元。让我们来了解一下网络架构
model.summary()
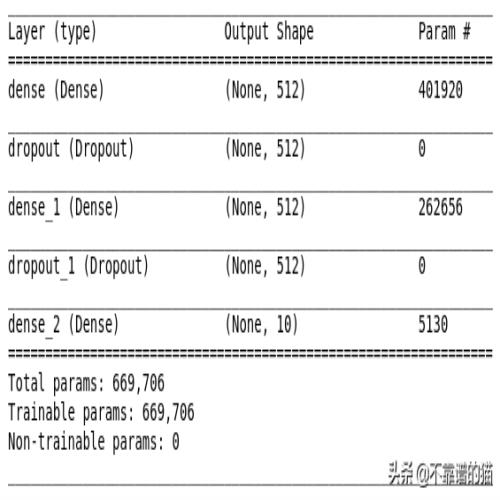
尽管问题很简单,但我们有相当多的参数需要训练(几乎约700,000),这也意味着相当大的计算能耗。卷积神经网络将解决降低计算复杂性的问题。
现在,编译机器学习模型:
model.compile(loss='categorical_crossentropy', optimizer=RMSprop(), metrics=['accuracy'])

开始训练机器学习模型:
history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test))
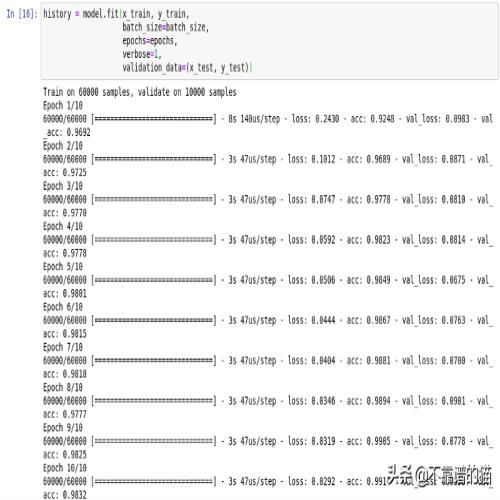
神经网络已经在单个RX 480上训练,具有可观的47us /step。相比之下,Nvidia Tesla K80的速度达到了us /step。
多GPU训练
另外,如果您的系统有多个GPU,则可以利用Keras功能,以减少培训时间,在不同的GPU之间拆分批处理。
要做到这一点,首先需要指定用于训练的GPU数量,声明一个环境变量(将以下命令放在单个单元格上并执行):
!export HIP_VISIBLE_DEVICES=0,1,...
从0到...的数字定义了用于训练的GPU。如果您想简单地禁用GPU加速:
!export HIP_VISIBLE_DEVICES=-1
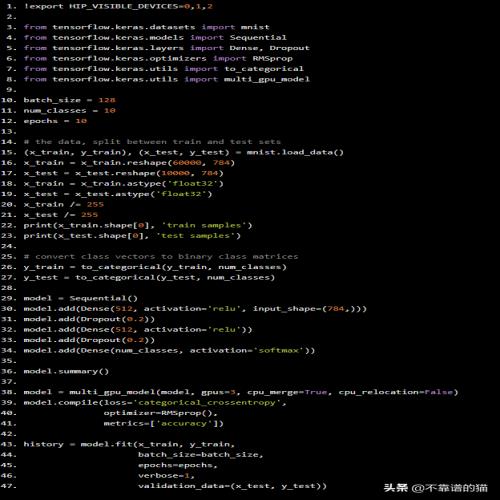
例如,如果您有3个GPU,Python示例如下
!export HIP_VISIBLE_DEVICES=0,1,2 from tensorflow.keras.datasets import mnist from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Dropout from tensorflow.keras.optimizers import RMSprop from tensorflow.keras.utils import to_categorical from tensorflow.keras.utils import multi_gpu_model batch_size = 128 num_classes = 10 epochs = 10 convert class vectors to binary class matrices y_train = to_categorical(y_train, num_classes) y_test = to_categorical(y_test, num_classes) model = Sequential() model.add(Dense(512, activation='relu', input_shape=(784,))) model.add(Dropout(0.2)) model.add(Dense(512, activation='relu')) model.add(Dropout(0.2)) model.add(Dense(num_classes, activation='softmax')) model.summary() model = multi_gpu_model(model, gpus=3, cpu_merge=True, cpu_relocation=False) model.compile(loss='categorical_crossentropy', optimizer=RMSprop(), metrics=['accuracy']) history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test))
结论
GPU市场正在快速变化,ROCm为研究人员,工程师和初创公司提供了非常强大的开源工具,降低了硬件设备的前期成本。







