

原文地址:https://mp.weixin.qq.com/s/n4oZjEROxUjO7zOrMITnLQ
作者:阿飞的博客

LinkedIn中的个人主页是访问量最多的页面之一,它允许其他人访问你的个人主页,从而了解你的专业技能,经验和兴趣等,所以确保用户访问主页时以最快的速度返回是非常重要的。这篇文章,将谈论LinkedIn如何调优,从而确保个人主页达到毫秒级别的响应速度。
背景
在单个数据中心中,个人主页的QPS能轻松的到达几十万以上,然而,当流量发生切换的时候(流量从一个数据中心切换到另一个数据中心),这些额外的负载就会被加到目标数据中心,导致QPS上扬,延迟增大。最终可能导致请求超时。个人主页变慢,就会拖慢其他依赖主页的接口,整个WEB服务性能出现级联反应。
整个切换过程各种问题非常多,这篇文章我们主要介绍在流量高峰期的时候,数据路由层碰到的垃圾收集性能问题,以及我们从CMS切换到G1的动机,我们还将对数据中心切换做进一步的优化。
配置CMS的路由器问题
LinkedIn的个人主页数据保存在Espresso中(LinkedIn使用的分布式、面向文档、水平扩容以及高可用的KV存储,你可以把它当作LinkedIn的MongoDB),当用户触发一个到Espresso的读写请求时, 路由器首先把请求定向到包含请求数据的存储节点。许多客户端选择从Master存储节点读取数据,仅是为了保证读取的一致性。然而,客户端也可以选择通过将读请求发送到从节点从而扩展读取能力,当然代价就是可能读取到过时的数据。
想要了解更多关于Espresso,请戳:https://engineering.linkedin.com/espresso/introducing-espresso-linkedins-hot-new-distributed-document-store
Identity服务,即提供主页数据的系统,过去一年该服务的QPS翻了一倍,由于这个服务海量的请求,导致它会对存储节点产生几十万QPS。此外,随着服务存活的时间越长,JVM中CMS的堆碎片化问题就越严重:

我们最初的想法是将老年代的大小翻倍提升到6G,这样可能帮助我们减少碎片化问题。但是,我们很快意识到,增加老年代容量只能延迟整体的清理时间,但是并不是杜绝碎片化问题和promotion failed,并且这次停顿达到了惊人的10.76秒,如下图所示:
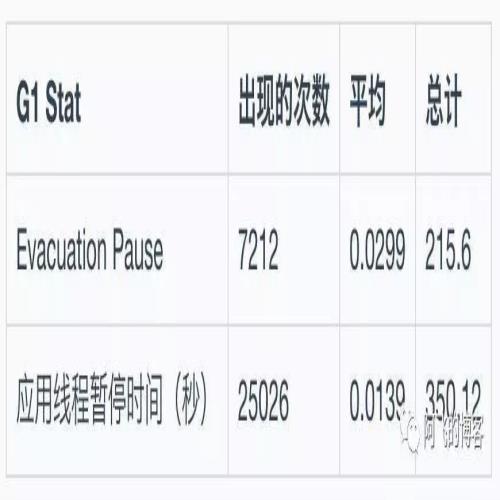
再看G1的一些统计信息--说明,G1的话,GC日志中出现 EvacuationPause就表示发生了YGC:
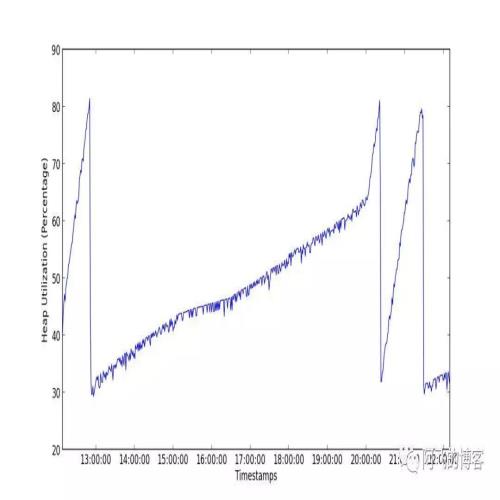
第二张图是G1堆的使用情况。我们可以看到,只有1次明显的波动,所以G1相比CMS优势明显:
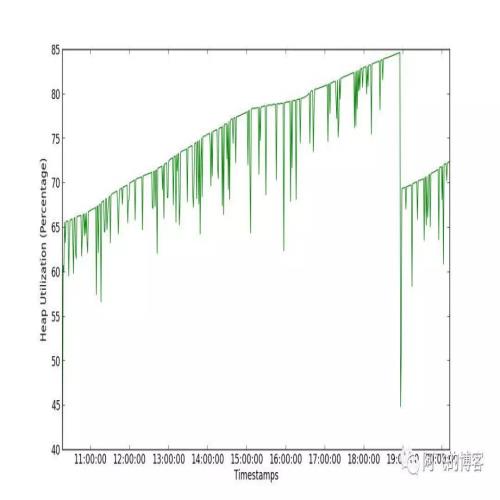
- CPU使用时间
我们再看CPU使用时间,如第一张图所示,是CMS的CPU使用时间,有3次的毛刺,这3次毛刺的时间点刚好是发生CMS GC的时候,事实上就是CMS的Remark非常耗时,且峰值达到了惊人的115ms。
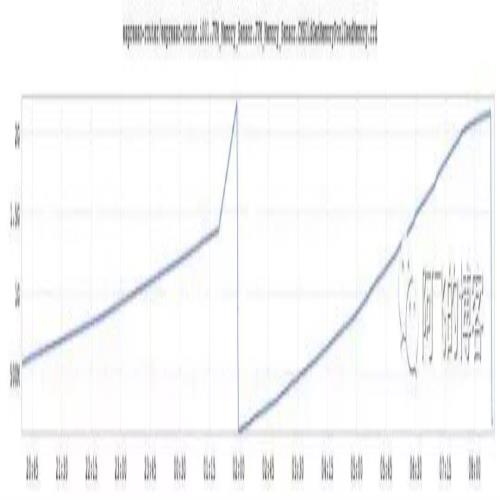

- Remark停顿时间
并发标记阶段就是GC从Root集合遍历并标记存活对象,这个是一个并发阶段,即应用线程和GC线程一起运行。然而,Remark阶段是STW的,意味着应用线程必须停顿,直到GC从并发标记开始到找出所有更新的引用。
因为并发收集应用停顿时间主要来自于Remark阶段(相比起Remark阶段,初始化标记阶段时间短很多),因此,调优让Remark停顿时间尽可能的低,就变得非常非常重要。对于Identity服务,CMS的Remark阶段平均停顿时间是150ms,而G1只有50ms。可见,相比CMS,G1并发标记阶段的停顿时间控制好很多。
调优效果
通过从CMS切换到G1,我们将平均停顿时间从150ms降低到50ms,并且大大减少了JVM碎片化问题(G1也不能完全避免),并且几乎没有观察到延迟毛刺。而且,将一个数据中心的流量全部切换到另一个数据中心的流量,也完全可以Hold住了。
这次调优已经证明,G1很大的缓解了性能问题,最大化吞吐量的同时,也最小化了延迟,现在服务的平均RT只有30ms。除了Identity服务之外,我们还在测量其他集群的性能指标,以了解它们将从G1中受益多少。
我目前是在职Java开发,如果你现在正在了解Java技术,想要学好Java,渴望成为一名Java开发工程师,在入门学习Java的过程当中缺乏基础的入门视频教程,你可以关注并私信我:01。我这里有一套最新的Java基础JavaSE的精讲视频教程,这套视频教程是我在年初的时候,根据市场技术栈需求录制的,非常的系统完整。







