

在《IBM Power8的单线程性能为何如此孱弱?》文中,我们了解了关于Power8的一些基础知识,下面我们将着重来看看到底是哪些缺陷拖累了IBM这位蓝色巨人。
Power8的阿喀琉斯之踵
对照着上一条微信中提到的取指效率关键影响因素,接下来分析一下IBM Power8的整个微结构前端设计。首先来看看指令缓存一侧的供应能力。
IBM的论文中介绍,Power8的每个核心具备32KB的一级指令缓存,每个周期可以读取8条指令,取指带宽为32Bytes。一级指令缓存为8路相联、16-bank的设计,如此大手笔的bank设计可以将8条指令同时读取,并将可能造成的访问冲突降到非常低的程度。此外,Power8的一级指令缓存也配备了指令预读取器,可以预取最多3个缓存块上地址连续的指令。只要一级指令高速缓存的预取和替换策略不出现设计失误,指令缓存一侧的指令供应能力应该是不成问题的。
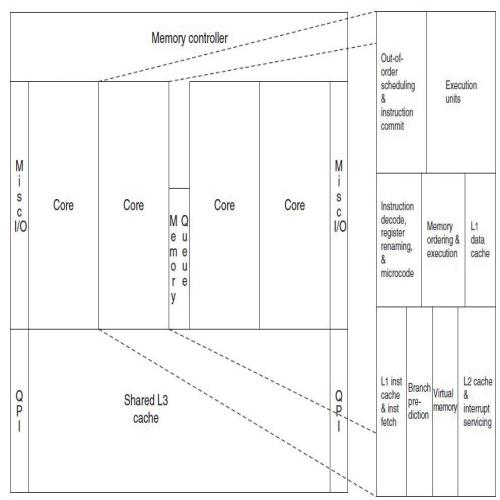
Nehalem的高层次布局图(high-level floorplan),可以看到分支预测器的大小与一级指令缓存及取指逻辑部分的大小相当。
第二个可能出问题的地方在于其分支预测准确率。笔者初步分析的结论是,Power8的分支预测准确率可以力敌Intel,瓶颈也不在这里。截止目前为止,从ARM到AMD、IBM到Intel都使用混合型分支预测器(hybrid branch predictor)。
因为分支指令的类型分为条件分支、无条件分支、函数调用/返回,间接跳转等,每一种分支指令的特征都不尽相同,因此现代CPU高性能微结构对每种分支都使用不同的预测器进行预测。多种预测器的混合就构成了混合型分支预测器。其中,无条件分支使用无条件分支专属的历史信息记录表,函数调用/返回类型的分支指令使用返回栈预测器(return stack predictor)。无条件分支每次都一定跳转因此无需预测分支方向,只需要使用分支目标地址缓冲区(BTB)来保存目标地址即可。
条件分支的情况则较为复杂,研究显示条件分支指令的跳转情况有时会出现一定的重复性规律,捕捉各个条件分支指令的跳转历史即可提供高准确率的预测,这部分历史信息保存在局部历史表中;但是有时条件分支指令的跳转情况和自身过去的历史无关,反而与周围相邻的一些分支指令的跳转情况有关,这部分的历史信息保存在全局历史表中。
这些分支预测器基本上都来自于公开的学术研究成果,对于分支指令的特征有了十多年的透彻研究,已经几无秘密可言,因此各家的预测准确率更多地取决于自身的一些实现技巧。与预测准确率直接相关的最重要参数之一便是各个历史记录表的大小,笔者估计IBM Power8在这个参数上估计位于均势地位,分支预测准确率的问题不会很大。
首先来看负责条件分支的部分。IBM Power8的锦标赛分支预测器使用了16K全局历史(GBHT)+16K局部历史(LBHT)+16K选择历史(GSEL)的豪华配置,对比Power7的16K+8K+8K的配置可以说是更上一层楼(龙芯最新一代的GS464E也使用了与Power8相同的规格),Intel使用的大小未公布,但可以谨慎乐观地认为在这一个点上Power8至少不会明显落后。
再来看看负责函数调用/返回指令预测的部分。Power8的返回栈预测器并非如Intel一样每个线程独享一个,而是多个SMT线程共享。在单线程状态和两路SMT状态下,每个线程使用32项,在四路SMT状态下就只有16项,八路SMT状态下就只有8项。单线程模式下的32项容量应该说是不错的,Intel的返回栈则是自身16项容量,但并不意味着Intel落后。
笔者见到的SPEC CPU上的返回栈预测器容量评估显示16项和32项容量差距很小,而且Intel还使用间接跳转预测器来作为容量满溢之后预测函数调用/返回的后备,使得返回栈预测器几乎可以说是“无限容量”。更为重要的是,在IBM的公开文档中未见提及使用返回栈修复技术,而只是简单地推测性压栈退栈。但返回栈修复这项技术对于返回栈的预测准确率来说至关重要,它旨在帮助返回栈消除由于错误的分支预测触发的后继函数调用/返回。
最后看看负责无条件分支、并且为所有分支指令提供快速目标地址的分支目标地址缓冲区(BTB),这里IBM的做法就让人有些摸不着头脑了。
在指出其潜在缺陷之前,先说一说其设计上的亮点。Power8的一级指令缓存上使用了许多工业级架构上使用的经典技术路预测(way prediction),称为IEAD(Instruction Effective Address Directory,指令有效地址目录)。这项技术的初衷是缩短一级高速缓存的访问延迟,首先推测性地访问一整组存储单元中的单单一个纵列,这样访问速度最快,如果发现访问的位置不对,再多花费一个周期的时间把整组的其他单元一起打开,总能寻找到要的那一个。这一项技术已经比较成熟,是一项值得赞扬的取指令优化设计。但更重要的是,分支目标地址缓冲区(BTB)在哪儿呢?
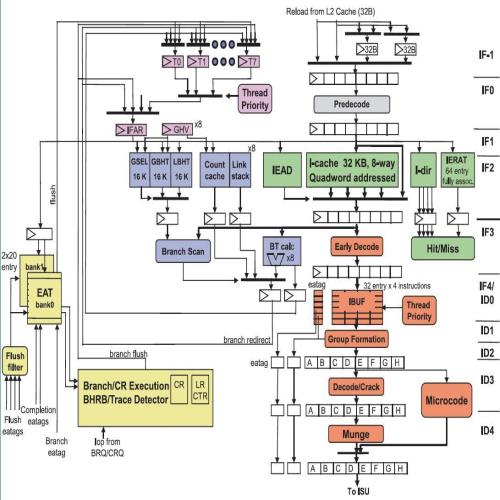
IBMPower8的微结构前端框图
第一个可以基本确认的缺陷出现在分支预测判断速度上。笔者在IBM的论文和框图中反复搜寻,均未找到分支目标地址缓冲区或者类似结构的存在。分支目标地址缓冲区的缺失可以说是灾难性的,每次碰到分支指令时都要等待分支预测器的预测结果才能进行取指,这意味着每次取指时一旦碰到跳转分支指令就要多消耗几个周期等待分支预测的结果和分支目标地址的重新计算。而早在上世纪80年代早期,相关的解决方案就已经出炉了,连早期的Cortex-A8都有采用,这个缓冲区会保存经过分支预测器确认的,一部分最常执行的分支指令目标地址,每次取指时不用等待分支预测器的新结果就可以按照过往预测结果继续取指,一本万利的买卖,各家谈论自己的微结构时都不会回避这一结构,为何IBM不见提及?如果没有分支目标地址缓冲区,那么分支预测的速度就会极大地影响前端的性能表现。
分支目标地址缓冲区的问题尚且可以说存疑,有可能Power8是真用了,但就是在跟大家玩捉迷藏。而给予Power8的单线程性能确确实实最沉重一击的地方,就是其分支预测的预测速度和相关补全机制的缺失。
下面的翻译内容来自在IBM内部期刊上的Power8论文:
“如果遇到跳转分支,需要花费3个周期才能得到下一次取指的地址,其中两个周期,对于这个线程来说不会有取指动作进行。然而,在SMT模式下,这两个周期一般会被分配给其他活跃线程,所以(吞吐量,笔者补充)没有损失。如果取上来的指令没有包含任何无条件分支或者是预测跳转的分支,那么下一次读取的地址就是顺序递增的地址,不会浪费取指周期。”
第一句话实际上是说Power8的分支预测需要3个周期才能输出结果,这与其他许多工业级微结构的设计类似,但是一般会加入大容量的分支目标地址缓冲区,或者使用大步进顺序预取指之类的方法补救,而Power8在此处简直是裸奔出场,在取到的8条指令中如果遇到哪怕一个跳转分支,那么在接下来2个周期的时间里就只等待分支预测结果,不再取指。这一下就让Power8的前端单线程指令效率在遇到跳转分支时跌为8指令/3周期,几乎成了单线程2.66发射的处理器!
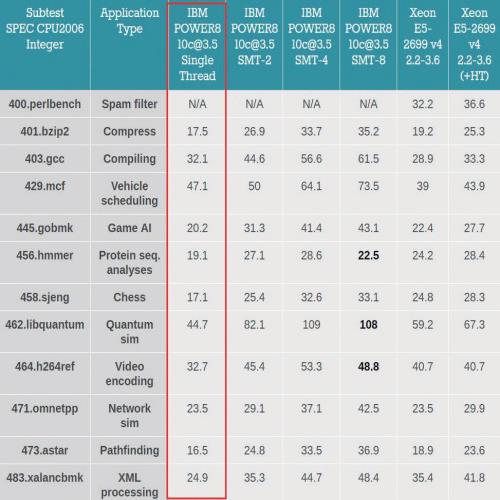
业内公开的Power8 SPEC2006测试结果,可见其3.5GHz的单线程性能甚至明显落后于2.2~3.6GHz的至强E5 v4系列,多线程性能倒是明显领先。
这一处让人大跌眼镜的设计,与IBM的宽发射宣传多少有点不太相符。根据IBM的解释,Power8可以使用其他线程来填补取指空白,但是这样并无益于单线程性能。前文中提到,此前的统计分析表明早期SPECint的跳转分支相互间隔只有5~8条指令,难道是这一趋势在最近的测试程序中发生了反转吗?
笔者又找到了德克萨斯大学奥斯汀分校在2009年发表于SPEC国际性能评估研讨会上的数据。强制预测每个分支均跳转和强制预测每个分支均不跳转相比,每个分支均跳转的失败率更低,这意味着至少多于一半的分支指令仍然偏向于跳转,可见这一趋势并未发生变化,并且还有分析表明SPECint 2006的基本块长度比SPECint 2000还有所缩减,也就是说,如果Power8的前端设计真的如同其论文中所述,那么取指单元运行在单线程模式下时将会极大概率地停顿,甚至是每次取指都停顿。
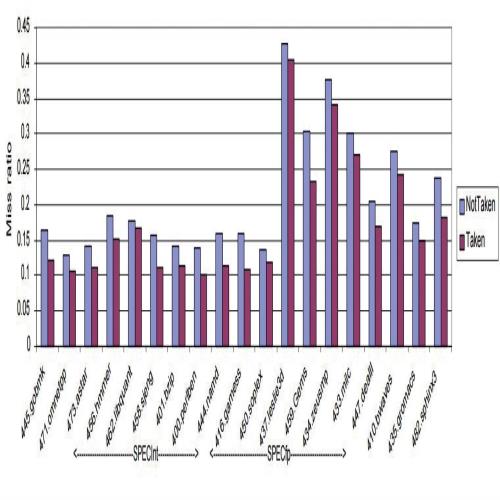
SPECint2006的分支预测失败率统计
翻阅Power7的文档,笔者发现Power7也存在同样的问题,论文中声明分支预测需要3个周期才能完成,但由于加入了128项分支目标地址缓存(BTAC),可以缓解遇到跳转分支时带来的取指停顿,其前端框架图中也明确绘制了这一结构。先不说这个分支目标地址缓存容量是否寒酸的问题,起码该有的是有的,而Power8的微结构当中这一关键结构却莫名其妙地不见踪影,倒是Power8的分支预测器尺寸比Power7明显加大。
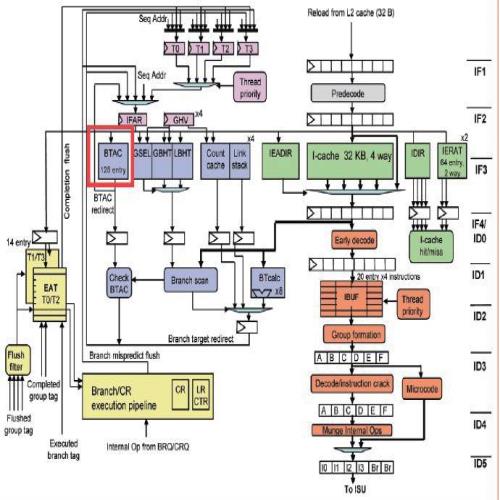
Power7的结构框图,红色框处就是分支目标地址缓存。
那么竞争对手Intel是怎么处理这个问题的呢。从早期的奔腾4开始,Intel吸收并实现了一项被称为踪迹缓存(trace cache)的技术,实现了每个周期跨越多个基本块进行取指,跳转分支以及跟随其后的指令会在踪迹缓存的处理下自动塌缩并连接成一条无间断的指令流,舒舒服服地提供给乱序执行引擎。这一技术后来更演化为闻名天下的uop cache,不仅保存无间断指令流,而且保存的指令都是x86不定长指令翻译而来的定长精简指令。由此笔者认为,Power8的取指前端设计在这一点上大大落后于Intel,IBM确确实实在单线程设计上略逊一筹。
侧重多线程性能的产物
必须声明的是,尽管笔者不看好Power8的单线程性能和其多少有些畸形的前端设计,但Power8仍然是一款非常强大、不容忽视的多线程服务器处理器。截至目前为止,Power8是现存的已量产设计中乱序多发射最激进、SMT宽度最宽的。
单线程性能与其乱序多发射的激进设计对比,出现现在这样出乎意料的孱弱,是Power8的设计团队有意权衡、侧重SMT多线程性能的结果。Power8对其取指问题的解释是,虽然单线程取指会引发额外停顿,但是每个核心支持8个线程,此时其他线程继续保持取指,就算每个单一线程轮流停顿,也可以维持住总体的吞吐量。由此可见,Power8是有意侧重SMT性能的处理器,并不适合进行侧重单线程性能的任务。文中谈及的微结构问题对于强大的IBM来说并非技术上不可解决,毕竟已经有多家成熟公开的方案,Power8的单线程性能问题最终应该归结到路线的选择和设计的取舍抛弃了单线程性能的缘故。







