

TiDB 是 PingCAP 公司研发的开源分布式关系型数据库,结合了传统的 RDBMS 和 NoSQL 的最佳特性。TiDB 兼容 MySQL,具备「分布式强一致性事务、在线弹性水平扩展、故障自恢复的高可用、跨数据中心多活」等核心特性,是大数据时代理想的数据库集群和云数据库解决方案。
UCloud 于今年 8 月 将 TiDB 公有云化并推出UCloud TiDB Service,当前使用的 TiDB 版本为 3.0.5 。UCloud TiDB Service相比裸机部署性能并无损耗,提供跨可用区高可用,对监控和Binlog等做了改造增强,使用户可获得一键创建、按需付费、灵活扩缩容的TiDB服务。
UCloud TiDB Service
为什么叫UCloud TiDB Service?这里强调Service是因为从公有云用户的角度来看,TiDB运行在公有云平台上,其实是以服务的形式呈现而不是一个物理资源。UCloud TiDB Service是一个支持原生MySQL协议的,高性能、跨可用区高可用、高可扩展的,面向Serverless的分布式数据库服务。
- 兼容原生MySQL协议
大多数情况下,无需修改代码即可从 MySQL 轻松迁移至 TiDB,分库分表后的 MySQL 集群亦可通过 TiDB 工具进行实时迁移。
- 跨可用区高可用
TiDB本身虽具备一定高可用性,但一般用户没有跨可用区部署条件。UCloud TiDB Service的所有组件都是跨可用区部署。TiDB所有模块的多实例部署能力,结合UCloud跨可用区部署能力,UCloud TiDB Service可抵御可用区级故障。
- 动态扩展
TiDB无论是计算节点还是存储节点都可以实现水平扩展,通过简单地增加新节点即可按需扩展吞吐或存储,轻松应对高并发、海量数据场景。
- Serverless
Serverless的产品形态让用户更加简单快捷的使用到TiDB,无需关心底层的物理资源,也无需关心底层分布部署的细节。
- 按需付费,接入成本低
无需指定CPU、内存、硬盘等资源,用户只需按实际使用的硬盘和存储量进行付费,节省了前期的硬件成本投入。
性能对比
我们做了一个测试,在相同物理配置(Intel Xeon E5-2620 v4, DDR4_16GB_2400MHz x12, U.2_NVMe_3.2TB x2 )和相同软件部署(TiDB x3, TiKV x3, PD x3 )情况下,测试条件为sysbench 512 threads, 32 tables, 1000万行。在裸机上部署TiDB和UCloud TiDB Service的性能对比如下表所示:
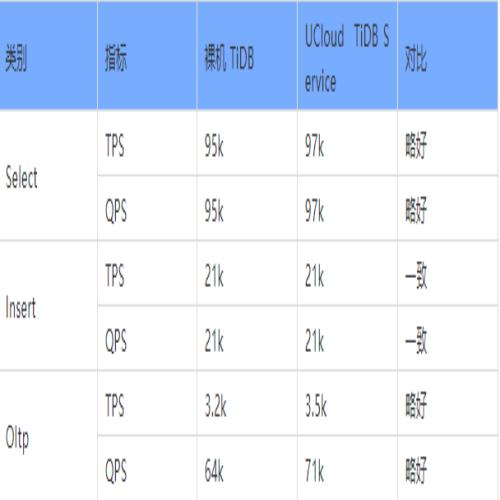
结果表明各项指标基本一致,UCloud TiDB Service 和裸机部署相比较,并没有带来性能损耗,有些指标表现略好。而在这背后,UCloud公有云后台做了哪些事情呢?
打造分布式数据库PaaS平台
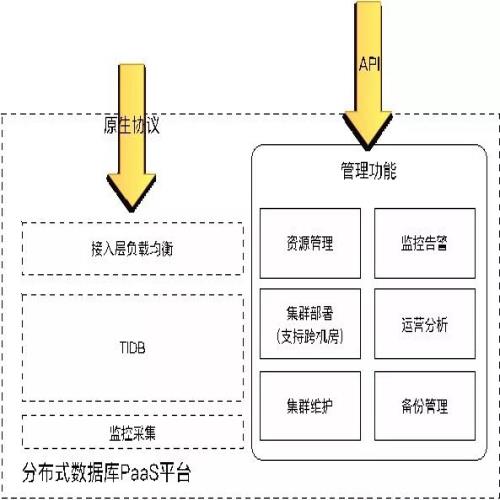
UCloud内部做了一个分布式数据库的PaaS平台(如上图),在管理功能上,左边第一部分有物理机的资源管理,包括每次创建实例的时候资源分配以及实例删除以后资源回收等等操作。第二部分是集群部署,一个创建过程先选取合适的物理机,检测上面的资源是否满足,满足以后分配特定的一些资源出来,然后再执行相应的创建工作,这里面要创建TiDB集群,相应的监控、LB层,以及部署在公有云上都是运行在用户VPC里面,需要做VPC网络初使化等工作。第三部分是集群维护,比如某台物理机有异常,就要把所有服务迁移到其他的节点面去。这里面主要涉及的是迁移、扩展、缩容这些工作。
右边是监控告警,主要用于对一些异常情况的及时通知告警管理;还有运营分析这块是UCloud数据库运营方面的管理。备份管理负责数据库的备份与恢复,用户可以设置比较详细的备份策略,比如何时备份如何备份等。
原生协议是MySQL本来的数据流,在这里我们加了一层负载均衡,主要有两个目的:一个是把IP地址统一成一个,用户不需要管理IP地址的切换;另外针对公有云服务传输做一些控制,主要是帐号和系统方面的控制。
跨可用区部署实现高可用
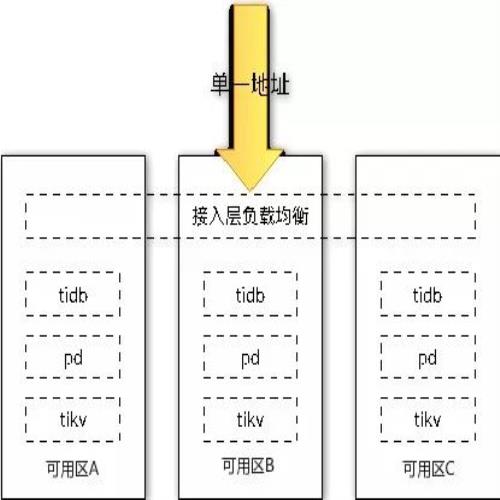
TiDB整体是由分布式 SQL 层(TiDB)、分布式 KV 存储引擎(TiKV)以及管理整个集群的 PD 模块组成。如图我们将TiDB的 所有组件进行跨可用区部署,并且提供单一高可用接入地址,单一地址的好处是用户不需要关注多地址,也不需要做地址之间的切换,另外一个好处是整个容灾过程对业务完全透明,比如要增加/缩掉一个TiDB节点,或者要迁移到另外一台机器时。有了统一地址虚IP之后,业务就完全不用考虑地址,所有的操作对用户完全透明。
对监控的改造
TiDB 本身使用了 Prometheus 作为监控和性能指标信息收集方案、Grafana 作为可视化组件进行展示、Alertmanager用于实现报警机制,但是都是单点部署, 并不具备容灾能力。我们将这三个模块都进行了高可用改造。大家知道,Grafana本身是没办法使用TiDB存储元数据的,我们对 Grafana源码进行了修改,改写了大量Multi-schema语句,并且去掉了将字段改小的操作,从而支持了Grafana使用TiDB存储元数据。
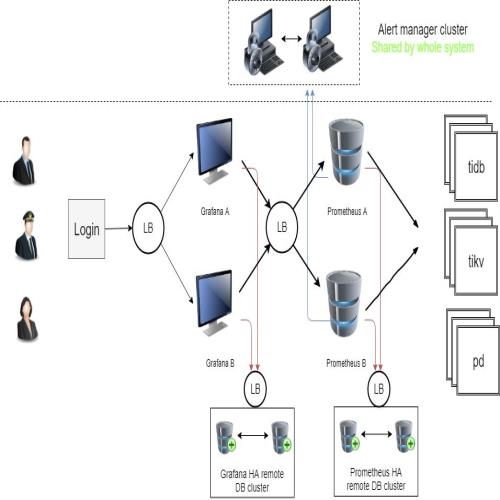
如图是一个用户业务监控系统,左边有一个LB,两个Grafana节点,我们通过LB连到Prometheus,从而实现远程高可用。
对Binlog的改造
有这样一个用户场景,将TiDB 数据导入已有的大数据集群作数据分析, 需要输出到 Kafka 的日志格式为 json, 以便 Flink 消费解析。由于Binlog 是 PB 格式,目前提供的 driver 只支持txt, mysql。
经过我们对Binlogdriver的改造之后,Binlog支持输出 Json 格式、支持将Json 格式日志写入Kafka。
品质改善和Bug修复
在打造TiDB服务期间,我们也相继发现解决了原生TiDB的一些小问题,从细节上提升产品品质。其中很多在官方后续的新版本中也已经陆续得到了改善和解决,例如:
- Drainer 输出 db.table 格式的语句 (fixed in 3.0);
- TiDB 升级到2.1以后时区变化;
- Syncer 在 retry 阶段不处理 SIGTERM (fixed);
- Syncer can’t decode set datatype (fixed);
- Drainer 只写一个partition 导致数据倾斜,我们可以启动多个drainer, 每个drainer 写一个DB;
- Raft store 单线程瓶颈 (fixed in 3.0);
- Binlog 开启/关闭10分钟内DDL慢 (fixed in 2.1.14)。
还有一些由于跟MySQL原生协议不同而导致语句理解上产生的问题,比如ID 分段自增、GC 时间导致连接中断、事务条数限制(单条 KV entry 不超过 6MB、总条数不超过 30w、总大小不超过 100MB)、失败自动重试等。这些问题经过UCloud内部的长时间打磨和积累,已经达到了一个相对成熟和稳定的形态。
TiDB管理模块

产品控制台向用户开放了TiDB的管理模块,分为四个部分:备份管理、恢复任务、用户管理、Binlog同步。具体如下:
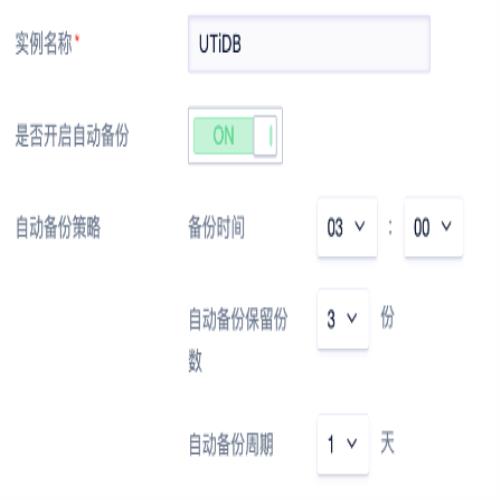
- 备份管理:创建 TiDB 实例时可以选择是否开启自动备份策略,备份策略包括备份时间、自动备份保留份数以及自动备份周期。除了自动备份,TiDB 还提供手动备份选择
- 恢复任务:TiDB 当前支持从备份文件恢复至一个新的 TiDB 实例,用户需要提前准备好新实例,恢复工作会覆盖新实例数据。
- 用户管理:TiDB提供给用户相应的权限管理,包括新增用户并初始化权限 、调整用户权限、删除非root用户等。
- Binlog同步:可将 TiDB 的增量数据实时同步到其他存储中,当前支持 MySQL,TiDB 作为目标存储。
总结
可以说TiDB 是为云而生的数据库,UCloud TiDB Service 在保证TiDB 性能没有损耗的前提下, 将 TiDB 以服务的形式提供给用户, 降低了用户使用门槛, 简化了用户管理, 提高了容灾能力。未来,UCloud将继续与PingCAP官方深度合作,致力于为云上数据库创造更多可能性。


点击下方“阅读原文”查看UCloud TiDB产品详情!







