

摘 要:阵列数据库系统是存储和分析大规模科学数据的常用技术方案。目前主流的阵列数据库中存储块分割策略采用固定边长作为块的边界,若边长过大会增加查询分析时定位Cell的时间,反之则产生过多的小块增加内存开销。本文提出一种改进的Chunk边长分割算法CLD,其通过减少读取数据时的磁道数以及预取技术提高阵列数据库系统的性能。在阵列数据库系统SciDB集群上的实验表明,在最优情况下系统性能提升了10.9%。
0 引言
在商业领域,基于关系模型的数据库管理系统(RDBMS,如SQLServer等)有广泛的应用,且取得了巨大的成功。但是,科学领域收集的数据结构与传统数据结构有很大不同,科学数据是以阵列为数据模型,与自然界中的数组模型类似。而商业数据管理系统适合关系型数据的处理,在应用到科学领域时将面临着许多难以克服的问题。同时,关系型数据库管理系统在存储和处理多维数组数据时改变了数据的天然数组结构,使后续的数据管理过程变得极其复杂[1-2],因此,RDBMS已经不能满足科学数据处理的需求。
以SciDB[3-5]为代表的阵列数据库系统,其主要应用领域为科学领域中超大规模阵列数据的存储和分析,其设计初衷是解决科学研究中数据量大、数据世袭等科学问题。通过SciDB等阵列数据库系统可以直接对科学数据进行分析,省略了数据从存储模块到分析模块之间的过渡,这是其与RDBMS最主要的区别之一。阵列数据库系统SciDB在开源社区力量的帮助下快速发展,其有商业版和社区版本,社区版本已经更新到14.12。与传统RDBMS不同的是,SciDB这样的阵列数据库系统能够为科学应用领域提供大规模的复杂分析支持,用以满足日益增长的需求。它采用数组数据模型(一种具有数学中数组特性的数据模型),支持多维数据,其基本组成单元是cell,各个cell有相同的值类型。cell的值可以是一个或多个标量值,也可以是一个或多个数组。
本文首先以SciDB为例介绍其自身实现的存储块(Chunk)的分割机制,针对其固有存储块分割机制的缺陷进行分析,提出一种改进的存储块的分割优化方案,并通过基准测试(Benchmark)实验与未优化的分割策略进行对比。
1 阵列数据库SciDB的存储块分割规则
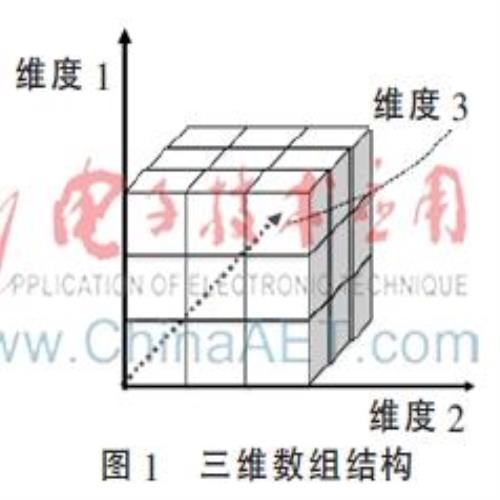
阵列数据库(Array DBMS)是以阵列(Array,亦称作数组)作为数据库“一等公民”。一个典型的3维数组结构如图1所示。通过数组模型可以实现数学概念中数组的一系列特定操作,比如特征值提取、交叉试验等,这些都是科学家分析和处理科学数据所需要进行的操作[6-7]。SciDB是一种采用无共享分布式架构、拥有可靠的消息和任务机制保障系统的阵列数据库;它采用了一种一次写入多次读取型的多维数组模型,并通过一种高效的版本控制方法,保证数组数据的动态更新和高效压缩存储;同时通过一种数组分块机制(Chunking)实现了数据的分布式存储。
SciDB可以是单节点也可以是分布式的。在分布式环境中,它把许多廉价的计算机组成一个集群,每个集群上可以有一个或者多个数据库实例,每个数据库实例仅处理存储在本地的数据。SciDB将节点分成了协调节点和工作节点两种类型。协调节点在每个集群中只存在于一台物理机上,它主要负责协调分发任务和收集各个节点返回的结果,同时进行结果整合和处理,并返回给客户端。集群中剩余的节点成为工作节点,主要负责本地数据的存储和分析。而Chunking则是SciDB中用于分配存储块的机制,其实现原理是把载入到SciDB中的数组分布到各个节点的SciDB实例(instance)上,每个节点通过自身的引擎对子数组进行分块,并且把分成的Chunk以轮询算法重新分布到集群的所有节点中。在这个过程中,每个SciDB节点需要对分配到本地的子数组进行Chunk的分割,而Chunk的大小范围由数组的每个维度的长度组成,如图2所示,Chunk的范围大小由数组的两个维度i、j组成,i和j的长度分别为i和j维度上cell的个数,图2中所示每个Chunk的i长度为5,j长度为8,因此Chunk范围大小为40,表示一个Chunk由40个cell组成。
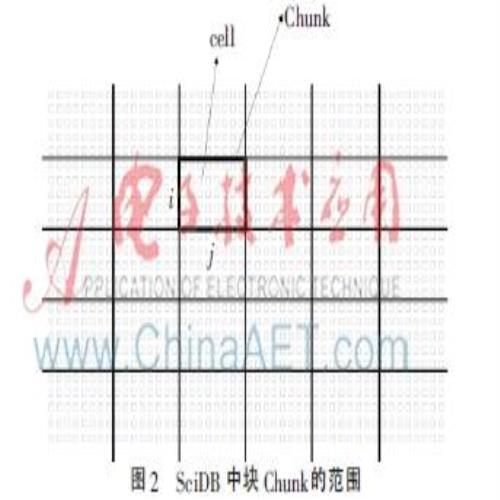
从图2可以看出一个Chunk大小由数组的所有维度边长大小所决定,因此Chunk大小的确定取决于每个维度的大小选择。而数组的Chunk大小会影响内存以及查询性能。例如,一个Chunk大小如果分配过大的话,Chunk范围内的cell总数就会增多,那么在进行查询分析时会增加定位cell的响应时间,影响查询性能;反之,如果一个Chunk大小分配过小,那么在有很多cell出现空值的情况下,由于每个cell都在内存中进行映射,而实际上并不是所有的cell都有意义,因此造成内存压力增大,甚至超过可用内存,进而引发其他异常错误。由此可见,合理选择Chunk大小可在某种程度上提升SciDB数据库的性能。在SciDB固有的存储块Chunk的分割策略中把每个Chunk的各个维度大小固定为1 000 000,其并没有考虑以上问题。针对SciDB原有的存储块Chunk分割策略,本文提出一种改进的Chunk大小分割方案,即块长度分割(Chunk Length Division,CLD)算法。
2 CLD算法
CLD算法的基本思想是根据载入的数据总量计算出磁盘每个柱面的容量大小,再由操作系统中的block大小得出初步的Chunk总数,接着取原数组中的每个维度长度的乘积与Chunk总数的比值得出Chunk的面积(cell总数),再根据原数组中各个维度的长度比值得出Chunk中的每条边长的比值,最后得出Chunk的每个维度长度。假设数组有n个维度,算法的符号定义如下:
SIZE:数组中的总数据大小。
d:存储总数据所需的最小磁道数。
Di:数组的第i个维度的边长,i=1,2,…,N。
ci:Chunk的第i维度的边长。
B:每个磁道能存储的block总数。
b:每个Chunk的cell总数。
s:每个Chunk的面积。
size:每个cell的大小。
则存储总数据所需的最小磁道数为:
则每个Chunk的面积s的计算过程为:
其中,
表示数组的面积。由于有些数组的各个维度的长度不尽相同,因此使Chunk的各个维度边长的比值与原数组的比值相同,可以减少在维度边界产生的细小的Chunk总数,因为这些细小的Chunk有可能包含的都是空cell值(Chunk碎片),会增加内存的开销。
因此,根据式(1)、(2)、(3)可以组成多元一次方程组,求解得出每个Chunk的维度边长的一组整数解。下面通过Benchmark对采用CLD算法后SciDB的内存和查询性能进行实验分析。
3 实验结果与分析
3.1 实验环境
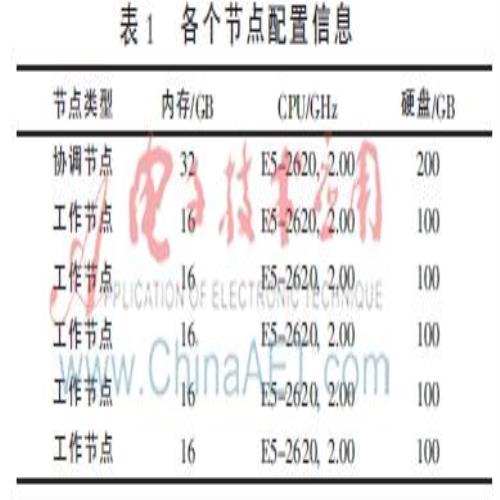
实验是在轻量级云平台Proxmox上完成的。Proxmox采用KVM作为其虚拟化方案,本实验构建了6个KVM虚拟机节点的集群,每个节点的CPU型号为Intel(R)Xeon(R)E5-2620,2.00 GHz。集群中有1台是协调节点,其内存为32 GB,硬盘大小为200 GB;剩余5台为工作节点,其内存为8 GB,硬盘大小为200 GB。表1为每个SciDB节点的基本配置信息。
3.2 实验设计
Benchmark测试通常被译成基准测试,基准测试是指通过设计科学的测试方法、测试工具和测试系统,实现对一类测试对象的某项性能指标进行定量的和可对比的测试。例如,对计算机CPU进行浮点运算、数据访问的带宽和延迟等指标的基准测试,可以使用户清楚地了解每一款CPU的运算性能及作业吞吐能力是否满足应用程序的要求。再如对数据库管理系统的ACID(原子性、一致性、独立性和持久性)、查询时间和联机事务处理能力等方面的性能指标进行基准测试,有助于使用者挑选最符合自己需求的数据库系统。作为一个能够评估科学数据库的Benchmark,其测试过程应该包括模拟所有的科学数据管理阶段,这些阶段包括:原始图像数据或传感数据的获取,这是原始数据的获取阶段;对原始数据进行相关查询阶段;把原始数据Cook成能够导出的数据集阶段;对Cook后的数据进行查询处理阶段。本实验采用SS-DB[8],它是一个标准的科学数据库管理系统的Benchmark,其用途是利用一系列相对复杂的用户自定义程序模拟操作面向数组的数据。SS-DB是通过模拟天文工作中的动作(如提取原始图像的像素、对观测值(Observations)进行聚集操作和分组操作、对组(Groups)进行复杂的几何操作等)达到测试的目的。因此,SS-DB测试完整地包含以上四个阶段,是较为可行的Benchmark测试方案。
3.3 结果与性能分析
实验测试数据为Tiny、Small和Normal三种数据集,其中Tiny数据集的大小为93 KB,总记录数为2 000条;Small数据集的大小为13 GB,总记录条数约为2.8亿条;Normal数据集的大小为123 GB,总记录数约为16亿条。对Tiny、Small和Normal三种数据集分别进行6次循环测试过程,每次测试都为冷启动,这样可以消除系统缓存带来的误差影响。表2展示了未优化前和采用CLD算法后的Benchmark测试结果。
表2中未加括号的数值为优化前各个查询的响应时间,括号内的数值为优化后的响应时间。总体来看,优化后的存储块分割策略比优化前在查询分析性能上有所改善,最优情况提高了10.9%。而分析Q1~Q6查询可知,其查询的复杂度由小到大,且这些分析查询语句都是CPU密集型的,对于以Chunk为基本处理单元的SciDB来说,Chunk存储块的大小对查询分析的性能有比较大的影响。但是,从实验结果可以发现,随着查询复杂度的提升,CLD算法带来的优势也随之下降。如Q5查询所涉及的表为数据集经过分割后的子表,其目的在于把观测值在空间上聚合成边长为100的切片,并找出观测值大于20的切片。可以看出这是相对比较复杂的一个操作,针对这种情况查询性能结果并不理想,原因是其查询响应时间中CPU处理的时间比重增大,而通过CLD算法节省的Chunk读取时间所占的比重减小,使总的性能下降。
CLD算法本质上是根据适合操作系统读写的block大小来设计Chunk的长度范围,它减少了磁盘获取数据需要扫描的磁道数,进而改善系统的性能。从实验结果可以看出,虽然应用CLD算法能够改善系统的性能,但是面对非常复杂的查询,其复杂分析时的计算时间比重会增大,通过CLD算法取得的性能表现也会随之下降。因此,CLD算法较适合的场景为中等或者轻量复杂度的分析查询。
4 结论
本文提出的CLD算法改进了原有SciDB的Chunk分割策略,通过SS-DB基准测试取得了不错的效果,最优情况下系统性能可以提升10.9%。CLD算法的主要思想是通过减少磁道访问次数以及预取技术减少Chunk读取的时间。然而算法中的参数并没有进行很好的调整,因此算法还有提高的可能性。另一方面,CLD算法针对复杂度较高的科学查询,如多表连接、大矩阵计算等效果并不理想。因此,如何提升复杂查询的性能需要进一步研究。
参考文献
[1] HEY T, TANSLEY S, TOLLE K. The fourth paradigm: data-intensive scientific discoveries[J]. Microsoft Research, 2009(1):153-164.
[2] GRAY J, LIU T D, DEWITT D, et al. Scientific data management in the coming decade[R]. 2005.
[3] STONEBRAKER M, BECLA J, DEWITT D, et al. Requirements for science data bases and SciDB[C]. Conference on Innovative Data Systems Research(CIDR)Perspectives, 2009:7-16.
[4] CUDRE-MAUROUX P, KIMURA H, CUDRE-MAUROUX P, et al. A demonstration of SciDB: a science-oriented DBMS[C]. VLDB, 2009,1534-1537.
[5] STONEBRAKER M, BROWN P, POLIAKOV A, et al. The architecture of SciDB[C]. Scientific and Statistical Database Management(SSDBM), 2011:1-16.
[6] CHANG C, ACHARYA A, SUSSMAN A,et al. T2: a customizable parallel database for multi-dimensional data[C]. Proceedings of ACM SIGMOD Record, 1998:58-66.
[7] STONEBRAKER M, BEAR C, CETINTEMEL U, et al. Zdonik: one size fits all? Part 2: benchmarking studies[C]. CIDR, 2007:173-184.
[8] CUDRE-MAUROUX P, KIMURA H, LIM K-T, et al. SS-DB: a standard science DBMS benchmark[R/OL]. (2012-08)[2015-03-05] http://www.xldb.org/science-benchmark/.







